Logistic regression is a fundamental statistical technique widely used in predictive modeling and machine learning. It helps determine the probability of a binary outcome (such as success/failure, yes/no, or 0/1) based on one or more predictor variables.
Whether you’re new to data science or a professional looking to build predictive models, mastering logistic regression with R is an essential step toward understanding classification algorithms and binary outcome analysis. In this guide, we will explore logistic regression using R programming, one of the most powerful and accessible tools for statistical computing.
Introduction to Logistic Regression
Logistic Regression is a core statistical method used to model the relationship between one or more independent variables and a categorical dependent variable. Unlike linear regression, which predicts continuous outcomes, logistic regression is designed for classification problems — where the output is categorical, often binary, such as “yes/no” or “success/failure.”
It estimates the probability that a given input belongs to a particular category, making it widely applicable in finance, healthcare, marketing, and social sciences.
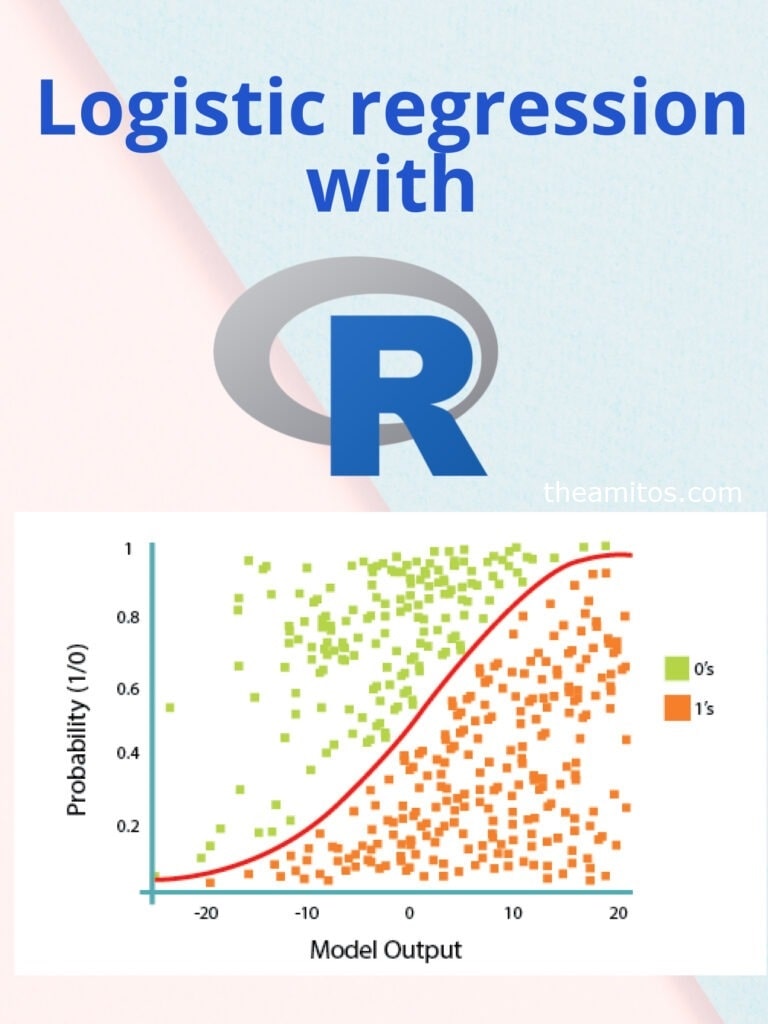
At its core, logistic regression uses a logit or sigmoid function to model the probability of an event occurring, mapping predicted values between 0 and 1. This probability can then be converted into class predictions using a threshold, typically 0.5. The coefficients represent how changes in predictors influence the log odds of the outcome, which can be interpreted as odds ratios.
Logistic regression is highly interpretable, efficient, and flexible—it performs well with small datasets and handles both continuous and categorical predictors. It also extends to more complex forms, such as multinomial and ordinal logistic regression.
Overall, logistic regression remains a cornerstone of predictive analytics, combining simplicity and statistical rigor for reliable classification and probability estimation.
When to Use Logistic Regression?
You should use logistic regression when:
- Your target variable is binary (e.g., “pass” or “fail”)
- You want to understand the relationship between the dependent variable and one or more independent variables
- You need to predict the probability of a specific event occurring
Examples:
- Predicting whether a customer will buy a product (yes/no)
- Determining if an email is spam or not
- Assessing patient disease risk (present/absent)
Logistic Regression Syntax in R
In R, logistic regression is implemented using the glm() function with the family argument set to binomial.
Syntax:
model <- glm(formula = target ~ predictors, family = "binomial", data = dataset)For example:
model <- glm(purchased ~ age + income, family = "binomial", data = marketing_data)Step-by-Step Guide to Performing Logistic Regression in R
R provides a highly flexible and intuitive environment for building logistic regression models. R makes it easy to handle large datasets, perform preprocessing, and interpret results with a few lines of code. Here’s a step-by-step overview of how to use logistic regression in R for binary classification.
Step 1: Loading the Data
You can either use built-in datasets like mtcars or Titanic, or load your own CSV data from your computer or an online source. Always begin by importing the dataset and checking its structure to understand variable types and missing values.
data <- read.csv("your_dataset.csv")
str(data)
This helps ensure your variables are correctly formatted—categorical variables as factors and numeric variables as continuous.
Step 2: Exploratory Data Analysis (EDA)
Before modeling, perform data cleaning, visualization, and summary statistics to understand data distribution and detect anomalies.
summary(data)
plot(data)
EDA helps in identifying outliers, correlations, and relationships between variables, ensuring better model accuracy later.
Step 3: Fitting a Logistic Regression Model
Use the glm() function with family = binomial to fit a logistic regression model.
model <- glm(target ~ predictor1 + predictor2, data = data, family = binomial)
summary(model)
This function estimates coefficients that describe how each predictor influences the probability of the target event occurring.
Step 4: Interpreting the Model Output
- Coefficients: The coefficients indicate the log-odds change in the outcome for a one-unit increase in the predictor, holding other variables constant. The p-values tell you whether each predictor is statistically significant in the model. To make interpretation easier, you can calculate odds ratios using the exponent of each coefficient:
exp(coef(model))These ratios express how much the odds of the event change for each predictor, making results more intuitive for decision-making.
Step 5: Model Diagnostics
Assess the model’s performance to ensure its predictive reliability. Key evaluation metrics include the Confusion Matrix, ROC Curve, and AUC (Area Under the Curve), along with measures like Accuracy, Sensitivity, and Specificity. In R, the caret package provides functions for easy evaluation:
library(caret)
pred <- predict(model, type = "response")
confusionMatrix(as.factor(pred > 0.5), as.factor(data$target))
A good logistic regression model should balance accuracy and interpretability, helping you make data-driven predictions with confidence.
Download PDF: Logistic Regression with R
Advanced Topics in Logistic Regression with R
1. Multicollinearity
Check for multicollinearity using the Variance Inflation Factor (VIF). Multicollinearity occurs when two or more independent variables in a regression model are highly correlated, which can distort regression coefficients and reduce model reliability. In R, use the car package:
library(car)
vif(model)
High VIF values indicate multicollinearity. To address this, remove correlated variables, combine them using techniques like principal component analysis, or restructure the dataset. Handling multicollinearity improves model interpretability, increases coefficient precision, and ensures more reliable predictions.
2. Feature Selection
Use stepwise selection methods (forward, backward, or both) to choose the most predictive variables. Stepwise selection helps improve model performance by including only the variables that contribute significantly to predicting the outcome, while removing those that add little or no value. This method balances model complexity and accuracy, reducing overfitting and improving interpretability. In R, you can perform stepwise selection easily using the step() function:
step(model, direction = "both")This approach evaluates variables iteratively and selects the optimal combination for the best predictive power.
3. Interaction Terms
Model interactions between predictors to capture more complex relationships and understand how the effect of one variable may change depending on the level of another variable. Interaction terms allow for more nuanced analysis in regression models, helping to reveal hidden patterns and dependencies in the data.
model_interaction <- glm(target ~ predictor1 * predictor2, data = data, family = binomial)4. Regularization Techniques
Use packages like glmnet for LASSO and Ridge regression, which help in variable selection, improve model interpretability, and prevent overfitting by penalizing large coefficients. These techniques are especially useful when dealing with datasets that have many features or multicollinearity. Regularization ensures that the model generalizes well to new data while keeping important predictors.
library(glmnet)
x <- model.matrix(target ~ ., data)[,-1]
y <- data$target
fit <- glmnet(x, y, family = "binomial", alpha = 1)
Model Evaluation Metrics
To understand the efficiency of your logistic regression model in R, evaluate it using various metrics:
Accuracy: This metric represents the proportion of correct predictions made by the model out of all predictions. It gives a general sense of model performance but can be misleading when dealing with imbalanced datasets, where one class dominates.
Precision and Recall: These metrics are particularly relevant in imbalanced datasets. Precision measures the proportion of true positive predictions among all positive predictions, while recall measures the proportion of actual positives that were correctly identified. Together, they provide a more detailed understanding of model performance for specific classes.
F1 Score: The F1 Score is the harmonic mean of precision and recall, combining both metrics into a single value. It is especially useful when you need a balance between precision and recall, such as in medical diagnosis or fraud detection.
AUC-ROC: The Area Under the Receiver Operating Characteristic Curve (AUC-ROC) represents classifier performance across different thresholds, showing how well the model distinguishes between classes.
library(pROC)
roc_obj <- roc(data$target, pred)
auc(roc_obj)
Visualizing Logistic Regression Results
Visualization significantly improves the interpretability of the logistic regression model, allowing analysts to better understand the relationship between predictors and the outcome variable. By plotting the data along with the fitted logistic curve, we can easily observe how changes in the predictor influence the probability of the target event occurring. In R, this can be achieved using the ggplot2 package.
library(ggplot2)
ggplot(data, aes(x = predictor1, y = target)) +
geom_point() +
stat_smooth(method = "glm", method.args = list(family = "binomial"), se = FALSE)
This approach visually demonstrates the fit of the model and highlights patterns in the data.
Dealing with Imbalanced Datasets
In many real-world scenarios, one class may heavily outweigh the other, which can lead to biased models and poor predictive performance. Strategies to handle this imbalance include:
Oversampling the minority class (e.g., SMOTE) to generate synthetic examples and increase representation.
Undersampling the majority class to reduce its dominance and balance the dataset.
Using class weights in modeling to penalize misclassification of minority class instances.
library(DMwR)
balanced_data <- SMOTE(target ~ ., data = data, perc.over = 100, perc.under = 200)
These approaches help improve model accuracy and generalization on imbalanced datasets.
Case Study: Predicting Heart Disease with Logistic Regression in R
Let’s say you are tasked with predicting the presence of heart disease in patients using important clinical parameters such as age, cholesterol levels, and blood pressure readings. Using logistic regression in R, you can follow a systematic approach to gain meaningful insights:
Fit the model: Start by identifying the most significant predictors among the clinical parameters. This helps determine which factors most strongly influence the likelihood of heart disease.
Generate predicted probabilities: Calculate the probability of heart disease for individual patients, providing a risk score that can guide further medical evaluation.
Assess model accuracy using ROC and a confusion matrix: Evaluate the performance of the logistic regression model by measuring sensitivity, specificity, and overall prediction accuracy.
Communicate actionable insights to healthcare providers: Present findings in a clear, interpretable manner so that clinicians can make informed decisions about patient care.
This process showcases how logistic regression in R can transform raw clinical data into actionable, evidence-based decisions that improve patient outcomes.
Conclusion
Logistic regression with R is a powerful and intuitive method for binary classification problems. It forms the foundation for more advanced machine learning techniques and is widely used across industries. By learning how to implement, interpret, and evaluate logistic regression models in R, students and professionals can enhance their analytical capabilities and drive data-informed decisions.